
使机器学习工作流自动化以在 Visual Studio 中注入 AI
了解 Microsoft 开发者事业部的数据科学家和工程师如何通过机器学习运营(MLOps)做法将成功的试验转变为高流量产品功能。
阅读完整案例挑战:从原型到大规模生产
经过 6 个月旨在提高开发者工作效率的 AI 和机器学习试验,Microsoft 开发者事业部的一小组应用数据科学家获得了一个模型,该模型可以主动预测开发者在编写代码时可能会调用的 C# 方法。
此成功的机器学习原型将成为 Visual Studio IntelliCode 的基础,这是一种 AI 辅助代码预测功能,但在此之前经过了严格的质量、可用性和缩放测试,以满足 Visual Studio 用户的要求。他们需要邀请工程团队创建机器学习平台并自动执行该过程。两个团队都需要采用 MLOps 区域性,从而将 DevOps 原则扩展到端到端机器学习生命周期。
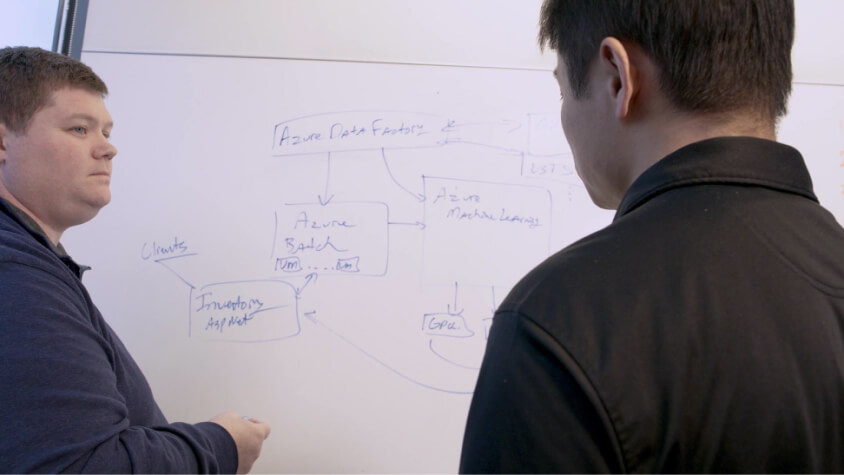
应用科学和工程团队共同生成了机器学习管道,以循环执行模型训练过程,并使应用科学团队在原型阶段手动完成的许多工作实现了自动化。通过该管道,IntelliCode 可扩展到支持 6 种编程语言,以定期使用大量开放源代码 GitHub 存储库中的代码示例来训练新模型。
"Clearly, we were going to be doing a lot of compute-intensive model training on very large data sets every month—making the need for an automated, scalable, end-to-end machine learning pipeline all that more evident."
Gearard Boland,数据和 AI 团队首席软件工程经理
利用 MLOps 中的见解
随着 IntelliCode 的推出,团队看到了设计更佳用户体验的机会: 根据每个客户的特定编码习惯创建团队完成模型。只要 Visual Studio 或 Visual Studio Code 用户发出请求,个性化这些机器学习模型都将需要自动按需训练和发布模型。为了使用现有管道大规模执行这些函数,团队使用了 Azure 服务,例如 Azure 机器学习、Azure 数据工厂、Azure Batch 和 Azure Pipelines。
"When we added support for custom models, the scalability and reliability of our training pipeline became even more important"
Gearard Boland,数据和 AI 团队首席软件工程经理
综合两种不同的观点
为生成机器学习管道,两个团队必须定义通用标准和准则,以确保他们使用通用语言、分享最佳做法并更好地协作。他们还必须了解彼此的项目方法。在数据科学团队进行试验性工作(快速循环执行模型创建)的同时,工程团队专注于确保 IntelliCode 满足 Visual Studio 用户对生产级功能的期望。
现在,整个机器学习管道(训练、评估、打包和部署)自动运行,并服务于 Visual Studio 和 Visual Studio Code 用户每月超过 9,000 的模型创建请求。团队正在寻找方法,希望能够使用自己的管道生成其他 AI 功能并将其整合其他 Microsoft 产品中,为客户提供更丰富的体验。